Now that we’ve got a working recipe parser, it’s time to see how well it works. I want to get a baseline idea of how my heuristic checker functions compared to a properly trained model, and I want to lay the groundwork for producing the training data I’m going to use down the road.
But first we need some training data. Fortunately for me, the internet is full of data science nerds who prep datasets for fun, and it just so happens that I found one that suits my needs quite well. The Recipe Box contains over 100,000 recipes scraped from several of the more popular recipe sites on the web.
But some cleaning still needs to be done. A quick scan of the dataset shows that there’s a lot more here than just recipe lines:
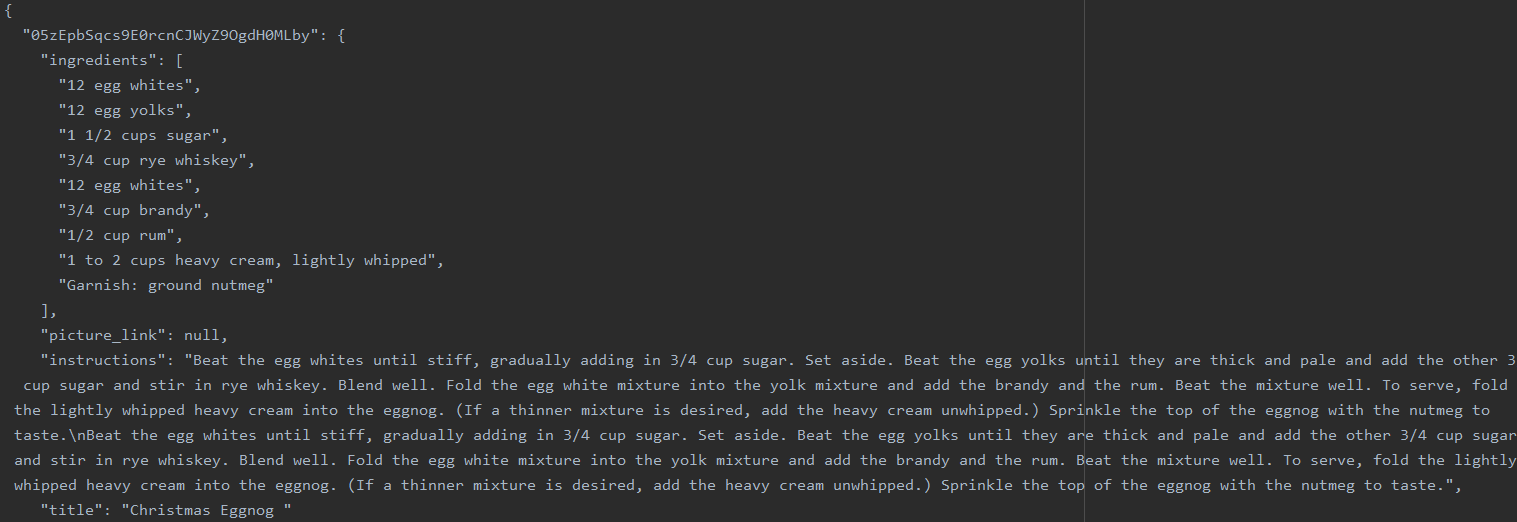
We don’t need the how-twos and the names; ideally all we want is the bare lines themselves. To that end, I wrote a simple set of functions that returns a list of ingredient lines of an arbitrary length:
def get_ingredients():
with open('recipes_raw_nosource_epi.json') as recipes_raw:
data = json.load(recipes_raw)
for k, v in data.items():
yield v['ingredients']
def generate_ingredient_dataset(length):
counter = 0
ingredient_list = []
raw_ingredients = get_ingredients()
while len(ingredient_list) < length:
current_ingredients = next(raw_ingredients)
ingredient_list.extend(current_ingredients)
return ingredient_list[:length] # there will probably be a few extras; clamp them
ingredient_dataset = generate_ingredient_dataset(100)
pp = pprint.PrettyPrinter()
with open('first_dataset.py', 'w') as first_dataset:
first_dataset.write("ingredient_dataset = " + pp.pformat(ingredient_dataset))This returns a list of 100 ingredient lines, like so (after I added a name to the list):

… and so on and so forth. Kudos to PrettyPrinter for doing most of the work here.
There were a few errors, some characters that Pycharm didn’t recognize. To be entirely honest, I’m not sure what they were supposed to be saying in an instance like this:

But we make do. I corrected them the best I could, and plan on taking them out for when I train the model properly. Without further ado, we upload our dataset to the parser, and….
We have an error.
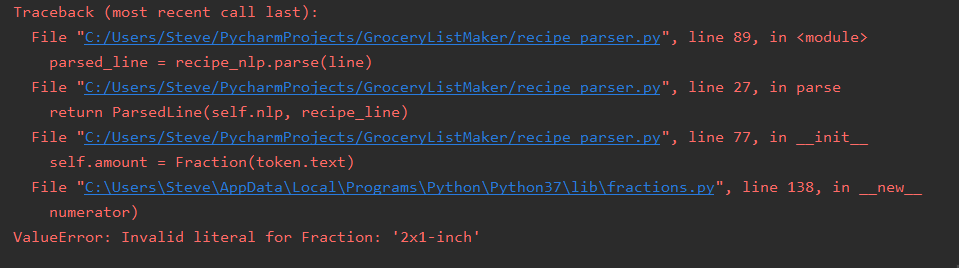
Ah, of course. All of the shortcuts I took earlier are catching up with me. Time to add in some catches.
try:
self.amount = Fraction(token.text)
except ValueError as err:
print("ValueError: {}".format(err))This fixed it, or at least prevented my program from stopping every time it caught an error. In reality, the '2x1-inch' isn’t a measurement at all (at least, not the way we want our program to recognize it). It’s another limitation of the method I’d designed, and by this point I was finding a lot of them.
But, I wanted some hard (or at least firm-ish) numbers, so I pressed on.
Next, I wrote a script to create a list of tuples pairing the original ingredient line with what the parser found:
training_set = []
recipe_nlp = RecipeNLP()
for line in ingredient_dataset:
parsed_line = recipe_nlp.parse(line)
training_set.append((line, [parsed_line.amount, parsed_line.measurement, parsed_line.ingredient]))
pp = pprint.PrettyPrinter()
pp.pprint(training_set)
with open('annotated_data.py', 'w') as annotated_file:
annotated_file.write(pp.pformat(training_set))This created a list of 100 tuples with the parser’s best guess for the ingredients and measurement. I labelled and formatted it, and here was the result:

From there, all I had to do was… go through all the data and correct by hand.
What fun.
This took less time than I thought, and revealed some other limitations in how I’d written the code, such as the fact that there isn’t a way to properly handle ingredients without a numbered measurement:

And some of the recipe lines were difficult for even me, a card-carrying human, to entirely work through. Or at least they were needlessly complex:

Aren’t humans wonderful? I’m frankly impressed it got as close as it did. This one’s also weird because, well what is the measurement? Slices? I went with slices, for now at least.
Another problem I quickly noticed was anytime there was an amount with a mixed number (e.g., '1 1/2 cups flour'), the program only caught the fraction part.
And I outsmarted myself in other ways:

So much for ignoring salt. Ah, well, that’s why we revise code.
After about a half hour or so, I’d successfully cleaned all the lines. Then, all that needed to be done was to compare the corrected set with the original attempt by the parser. This was done easily enough:
correct = 0
for i in range(len(annotated_data)):
line_is_correct = True
for j in range(len(annotated_data[i][1])):
if annotated_data[i][1][j] != annotated_data_corrected[i][1][j]:
line_is_correct = False
if line_is_correct:
correct += 1
print("found {} correct out of {}".format(correct, len(annotated_data)))
print("for a total correct score of {}".format(correct/(len(annotated_data))))And after all that work, what was our score?

60% correct. That’s… about what I’d thought, and better than I’d feared. But it’s still not great, and I certainly wouldn’t be brandishing this program around yet. Something that only gets an ingredient right 60% of the time isn’t really of any use to anyone.
Now it’s time to see how we can make this thing better.
(If you’d like to read the rest of this series, here’s Part 1, Part 2, and Part 3)