And now, the moment we’ve all been waiting for. It’s time to see if spaCy can learn what an INGREDIENT is.
My first step was to use the program I’d made from my previous post and use it to annotate the rest of my recipe lines. And I’m pleased to say that it worked, for the most part. There were a few errors that I’d like to iron out, but the process was quick and relatively painless.
Okay, it was still annoying, but I don’t think there’s really any way around that. I timed myself, and it took me roughly 8 minutes to annotate all ingredients, and about half that time for the CARDINAL and QUANTITY classes (because there were less of them). Taken together, that made 100 lines of annotated data in about 20 minutes of work. Not bad.
Then it was time for training. I again took the code from spaCy’s example documentation. It’s largely the same as the example for updating a new entity class, with a few minor changes such as adding the additional entity. But the basic loop is still the same: batch up a group of examples, have the model guess what they are, compare that to the annotations, adjust weights accordingly.
I had a few false starts, because some of the labelled entities were overlapping. This was an easy enough to fix by hand, but I made a note to write something later to do this automatically.
After a while…
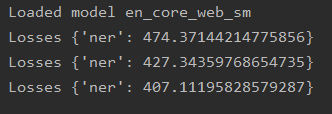
It’s training! I left it alone for a few minutes and…
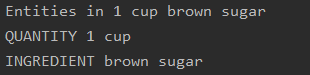
It worked! At least for this example. So far so good. Now I needed a new way to test it, so I needed to create additional data. This was something I’ve been meaning to do for a while now anyway. I went back and modified my original script for generating recipe lines so it would do so randomly:
def random_ingredients():
with open('recipes_raw_nosource_epi.json') as recipes_raw:
data = json.load(recipes_raw)
rand_recipe = random.choice(list(data.items()))
return rand_recipe[1]['ingredients']
def generate_ingredient_dataset(length):
counter = 0
ingredient_list = []
while len(ingredient_list) < length:
current_ingredients = random_ingredients()
ingredient_list.extend(current_ingredients)
return ingredient_list[:length] # there will probably be a few extras; clamp themThis is slow to execute because there are a lot of recipes that need to be added to this list. At the moment, though, I’m willing to overlook it because I’m not going to need to do this very much. If I need to make these randomized lists more regularly, I might need to figure out a faster way to do this.
But it works:
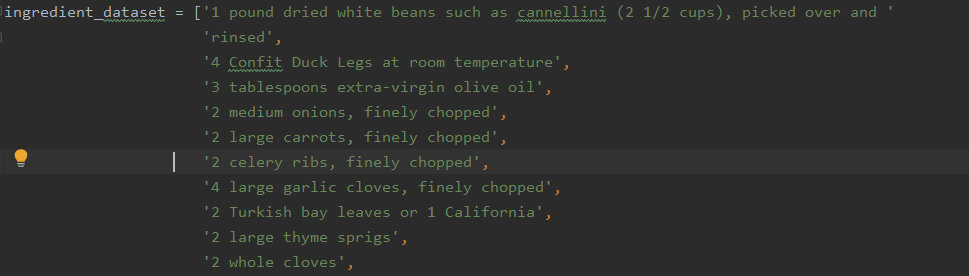
I then began annotating the data. It took about the same amount of time as my previous work, with a little extra because I very foolishly forgot to change the annotation tag a few times, meaning I labelled everything CARDINAL and had to go back. When I was done beating my head against the wall, I corrected my mistake, ran it again, and it worked.

One thing I’m realizing is that I should maybe add an additional category for comments because otherwise extremely similar ingredients are going to be read differently. Alternately, I could add adjectives as ingredients. Maybe there’s no need to reinvent the wheel here.
I then wrote some code to compare the model’s performance with the annotated data:
import spacy
from combined_data import annotated_for_testing_with_all, new_annotated_data
test_model = spacy.load('ingredient_test')
success = {
"CARDINAL": [0, 0], # first num is success, second num is all attempts
"QUANTITY": [0, 0],
"INGREDIENT": [0, 0]
}
for line in annotated_for_testing_with_all:
doc = test_model(line[0])
line[1]['entities'].sort() # we sort because the annotations are not originally in order
for ent, tup in zip(doc.ents, line[1]['entities']):
found_annotation = (ent.start_char, ent.end_char, ent.label_)
if found_annotation == tup:
success[tup[2]][0] += 1
success[tup[2]][1] += 1
print()
cardinal = success['CARDINAL']
quantity = success['QUANTITY']
ingredient = success['INGREDIENT']
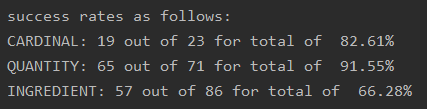
print("success rates as follows")
print(f"CARDINAL: {cardinal[0]} out of {cardinal[1]} for total of {cardinal[0]/cardinal[1] * 100: .2f}%")
print(f"QUANTITY: {quantity[0]} out of {quantity[1]} for total of {quantity[0]/quantity[1] * 100: .2f}%")
print(f"INGREDIENT: {ingredient[0]} out of {ingredient[1]} for total of {ingredient[0]/ingredient[1] * 100: .2f}%")For every line in the test, the ingredient model evaluates what it thinks the entities are. It then compares them to the actual examples to see if it got them right. The ultimate results are printed at the end. And what are those results?
…drumroll please…
Well, it’s not terrible.
It makes sense that QUANTITY and CARDINAL did much better, because both of them were already existing categories, and spaCy’s documentation notes that NER will need fewer examples of already existing categories to improve them. I’m not sure what to account for the difference between the two, however.
As for INGREDIENT, well I’m going to say that it’s still too early to tell. After all, this is only 100 examples, and I’m going to try to triple that amount or more. It will be interesting to see how the model improves with more examples.
To get a better idea of what sorts of errors it was getting, I added a quick line to print out the ingredient if it did not match correctly. The results were… unexpected.
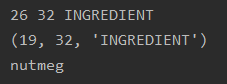
Hmm, that seems… accurate. I checked my annotations and realized that I had marked the ingredient as “ground nutmeg.” A technically incorrect result, but one that any human would have no trouble understanding. Let’s look at another “error.”
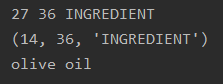
Another one that seems like it should be right at first glance. I checked and realized that I had annotated it as “extra-virgin olive oil.” Again, the program marked it as technically incorrect when the meaning was right. (Various culinary minds may remark here on the importance of “extra-virgin” to an olive oil. I leave them to this very important task.)
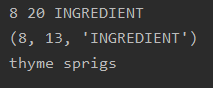
This one was annoying, because I realized that I had just marked “thyme” as the ingredient. But why had I not marked “thyme sprigs” as the ingredient, when I added modifiers to extra-virgin olive oil and ground nutmeg?
At this point, I was beginning to see that I had a problem. The entity recognizer was performing better than I had expected, and its failures were due in part to an inconsistent style of labelling done by yours truly. I’m realizing now that I have no central philosophy behind what defines an INGREDIENT versus what would be considered a modifier or an adjective to said ingredient.
But at the same time, this is a more complicated problem than it first might appear. Take sugar as an example. I wouldn’t necessarily want my program to group all kinds of sugar together; there are too many different kinds, and a recipe that calls for “brown sugar” won’t be the same if “white sugar” is recorded. At the same time, “white sugar” is often written as just “sugar” or even “granulated sugar.” On the other hand, a user of this program will see “sugar” and assume white sugar, so maybe it’s best to just record “sugar” unless it’s “brown sugar.” On the other other hand….
And so we go. I’ve been pushing foward with the project valiantly for a while now, but I think it’s time for me to take a step back and take stock of what I’ve done and how I want to move forward. Initial results have been incredibly encouraging, but if I want this to be something that other people will use (and I hope it would be), then I’m going to have to be more specific and thoughtful about how I train these models to store information. I need, essentially, some guiding philosophy to the whole enterprise. So that’s my next step: codify everything that I’ve been doing so far, and everywhere I want to go, and chart a course in that direction.
Plus, I need to look more closely at spaCy’s documentation. I’ve got a nagging feeling that some of the things I’ve been doing here have built-in functions for their use and that I may be reinventing the wheel a bit….