After having successfully shown that I could train the spaCy model to a wider definition of 'QUANTITY', I still had to iron out some details. The most pressing of which was the fact that spaCy’s model seemed to have learned that any number/word combination equated to a 'QUANTITY' entity. This was fine for something like '1 cup' but it was also reading '6 carrots' or '1 egg' as a 'QUANTITY', which I did not want. In order to better define the difference between a quantity and a base number, I added some additional training data to my set, specifically involving instances where a number/word pair was not a 'QUANTITY' positive:
('12 egg whites', {"entities": [(0, 2, "CARDINAL")]}),
('12 egg yolks', {"entities": [(0, 2, "CARDINAL")]}),
('Garnish: ground nutmeg', {"entities": []}),
('18 fresh chestnuts', {"entities": [(0, 2, "CARDINAL")]}),
('1 bay leaf', {"entities": [(0, 1, "CARDINAL")]}),
('6 medium carrots, peeled, cut into 1-inch pieces', {"entities": [(0, 1, "CARDINAL"), (35, 48, "QUANTITY")]}),
('4 or 5 slices brioche, or good quality white bread (I like Pepperidge Farm), 1/4 inch thick, crusts removed',
{"entities": [(0, 13, "QUANTITY"), (77, 85, "QUANTITY")]}),
('3 extra-large eggs', {"entities": [(0, 1, "CARDINAL")]}),
('2 extra-large egg yolks', {"entities": [(0, 1, "CARDINAL")]})I fed this information into the program (along with my original data), and…

Success! Three important examples to note here.
- The model successfully recognizes “cups” as quantity (see the first line).
- The model successfully recognizes examples without measurements as
'CARDINAL'rather than'QUANTITY', as you can see on line 5. - The model no longer recognizes “Garnish” as an
'NORP'entity. While on one hand, this is good because that was a wrong read in the first place, on another, broader note, this is bad because it indicates that the model is forgetting other examples. That’s something that we need to fix.
I subsequently ran it through the entire 100 line set I’ve been working with, and everything seemed to be working well.
At this point, there are several things that I need to do:
- I need to create a much larger test set, and, more broadly, figure out how to annotate data as efficiently as possible.
- I need to add in the “ingredient” entity for recognition
Both of these are going to require an easier way to generate large amounts of test data. After all, while spaCy notes that you only need a “handful” of examples to adjust or improve the accuracy of an existing entity category, in order to create a new one, it recommends at least a “few hundred” examples. Writing out all the code and boilerplate for that many examples is tiring. My solution? Make spaCy do most of the heavy lifting for us.
Using spaCy to Help Make our Training Data
Because spaCy’s NER saves the beginning, ending, and label for all the entities it finds, I figured it woudl be fairly easy to reverse engineer that into auto-generating the scaffolding for a much larger training set. To be clear, having spaCy generate a training set and then feeding that set back again wouldn’t do anything. However, it would come in handy if we want to create a list of partially annotated examples that we can then add our own annotations to. That way, we can ensure that spaCy doesn’t forget what we’ve already taught it.
I feel like this still sounds a bit circular when I write it out, so here’s some code:
nlp = spacy.load("en_core_web_sm") # or any model we want
AUTO_TRAIN_DATA = []
for line in ingredient_dataset:
doc = nlp(line)
AUTO_TRAIN_DATA.append((line, {"entities": [(ent.start_char, ent.end_char, ent.label_) for ent in doc.ents]}))This creates training data in the same format as spaCy accepts, and in a fraction of the time it would take to do it by hand. I ran this code twice: first with the original 'en_core_web_sm' model, and second with my trained model. This produced two similar, but not exactly the same, training sets:
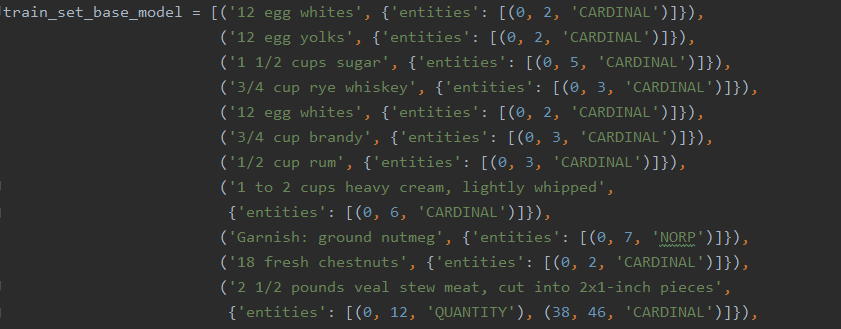
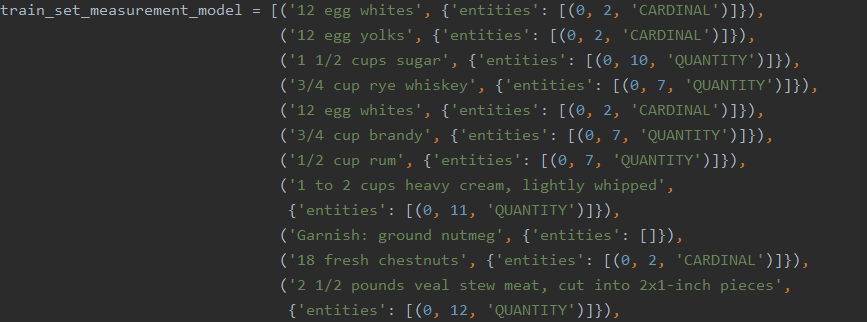
The top is the original spaCy model, and the bottom is the trained model. Note the differences between them. For example, the trained model reads the third line correctly as a 'QUANTITY', while the original model simply records a 'CARDINAL'. Likewise, the orginal model once again reads 'Garnish' as 'NORP'. The great nation of Garn has returned.
The next step was the combine these two models together in such a way as to preserve the knowledge lost from the original model, while also keeping what the trained model has learned. Honestly, I think I made this process much more challenging than I should have; there was a lot of headscratching and 4x nested lists and a bunch of stuff that didn’t work. But eventually I took a step back and realized that the solution was actually pretty simple. Essentially, all I wanted to do was create a model that understood the modified 'QUANTITY' and 'CARDINAL' classes, without changing anything else. In order to do that, I just had to combine the 'CARDINAL' and 'QUANTITY' entities from the trained set with the rest of the entities from the original set.
Here’s what I came up with:
mapped = zip(train_set_base_model, train_set_measurement_model)
train_set_final_model = []
for pair in mapped:
print(pair)
recipe_line = pair[0][0]
print(pair[0][1], pair[1][1])
new_entity_dict = {"entities": pair[1][1]["entities"]}
do_not_copy = ["CARDINAL", "QUANTITY"]
for entity, annotation_list in pair[0][1].items(): # loop through the original model's list
for annotation in annotation_list:
if annotation[2] not in do_not_copy:
print(annotation)
new_entity_dict["entities"].append(annotation)
train_set_final_model.append((recipe_line, new_entity_dict))
with open('combined_data.py', 'w') as combined_data:
pp = pprint.PrettyPrinter()
combined_data.write(pp.pformat(train_set_final_model))This loops through all of the dictionary entries and takes all of the entities that are not 'CARDINAL' or 'QUANTITY' (i.e., all entities that our improved model didn’t touch/forgot about) and adds them to the second model, creating a combined set of data that hopefully has the best of both worlds. This is the model that we will annotate for our new 'INGREDIENT' category.
But first, it needs to be tested to see if it works. Scanning through the data to make sure that everything is okay…

A few small issues here and there. The model can’t tell if entities are overlapping, and I had to go through and remove some of them by hand. But overall, it worked pretty well. I ran the first 20 lines through as training, and then ran the rest through as a test.

Success! You can see here that it’s correctly still reading “Spanish,” while also taking the corrected “QUANTITY” measurements in.
Although I am starting to wonder about how necessary this all was; in fact I’m starting to doubt the need at all. Looking through the text, many of the additional entities that spaCy found are just items that I’m going to make the INGREDIENT entity anyway; the model is likely to forget what they are regardless. Plus, I’m not sure that a recipe recognizer really needs to know that London is a city.
However, this work was still pretty useful, as I created a much longer training set and wrote code that partially automated the annotation process. The next step will be to go through this and annotate by hand the ingredient entity. Which, I don’t think there’s really any way around that, but with the scaffolding in place, it shouldn’t be that bad.